Building Skillsmith with Multi-Agent Orchestration
How Skillsmith used Claude-Flow V3, its SPARC methodology, hive-mind execution, wave-based delivery, as well as custom skills like Plan-Review — to ship 159 commits across 534 Claude Code sessions. A guide to How-I-AI in practice.

Skillsmith was built to be agent-native for agent frameworks like Claude Code, and it’s development has been orchestrated by Claude Flow V3. This post is a behind-the-scenes look at how that has worked out in the first 60 days — the specific patterns used, what they caught, and what the numbers look like so far.
The short version: 159 commits, 534 sessions, and two critical architectural bugs caught before a single line of code was written.
Key Takeaways
- Claude Flow V3 turns Claude Code from an agent framework into a coordinated multi-agent engineering system via SPARC, hive-mind execution, wave-based delivery, and intelligent model routing
- SPARC methodology is mandatory in Skillsmith for any infrastructure change — research-first planning catches potential bugs at the architecture stage, where they’re cheap to fix
- Plan-Review (triggered for each implementation plan, creates 3 perspectives before any code to predict failure points) has resulted in a ~60X return on time: 5 minutes of review prevented hours of production debugging such as avoided anti-patterns, regressions, conflicts, or blockers
- Wave-based delivery bundles similar tickets together for shared context with risk-first ordering and branch stacking which ships multi-dependency epics in hours rather than days or weeks
- MEMORY.md + SQLite persistence gives each session 94% of prior context, compounding across hundreds of sessions into institutional knowledge, and no sweat on auto-compact on sessions
- The dogfooding loop — Skillsmith is built with its own skills — creating a direct quality feedback cycle between the toolchain and the product
What Skillsmith Is (and Why We Dogfood It)
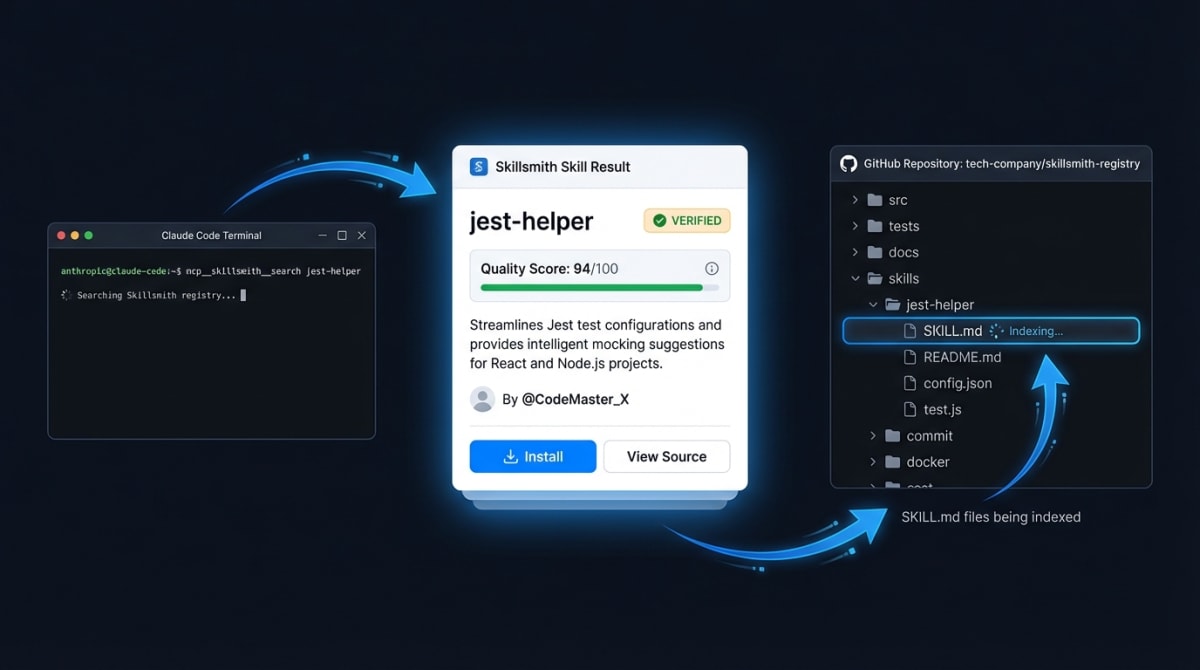
Skillsmith is an MCP server and a CLI that enables an agent framework to discover, evaluate, and install agent skills from a curated registry — with trust scoring, security scanning, and contextual recommendations. It also includes command line tools to create, publish, or optimize skills for authors.
The problem it solves: finding and trusting a skill today is like npm in 2010 — no curation, no scoring, no safety net. We’ve indexed 50,000+ skills from GitHub with sub-100ms search latency, a security scan on every install. Hot tip - do not just download and install markdown files from the internet. You’re welcome.
| Tool | What it does |
|---|---|
search |
Semantic skill discovery |
install_skill |
Vetted install to ~/.claude/skills/ |
recommend |
Context-aware suggestions |
validate |
SKILL.md structure verification |
compare |
Side-by-side quality scoring |
Building Skillsmith with its own skills creates a tight feedback loop: every pattern we ship to users, we live with ourselves first. If something is painful to use, we feel it immediately.
Claude Flow V3: From Agents to Agent System
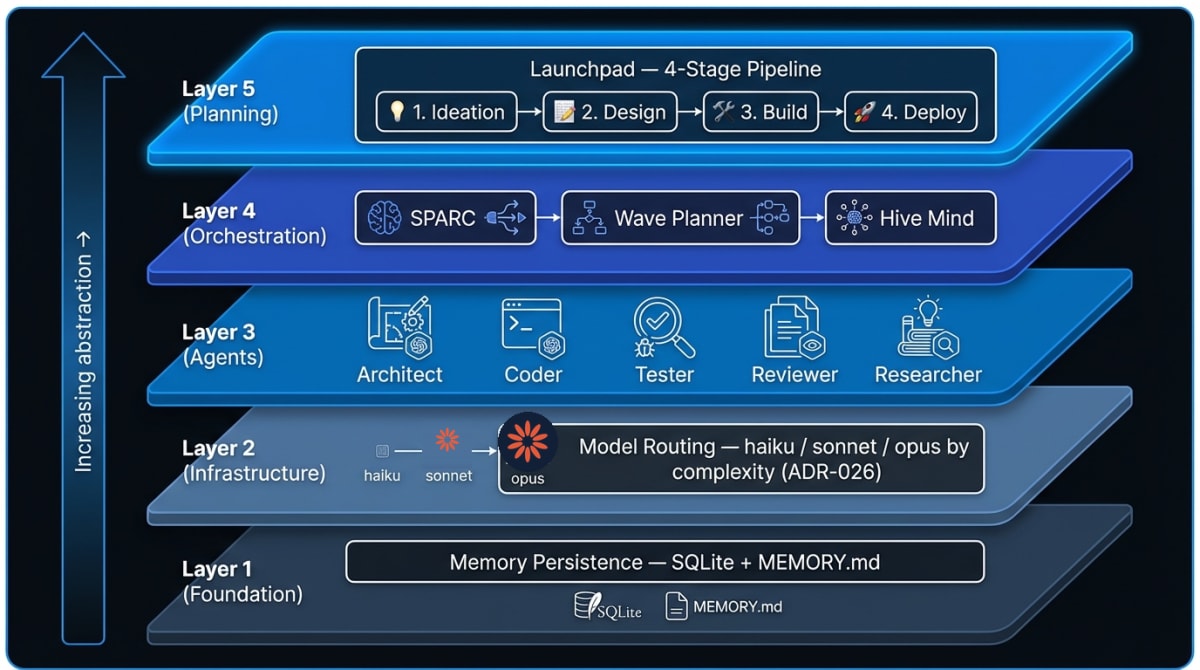
Claude Flow V3 is a multi-agent orchestration framework that ships as an MCP server, SQLite db, as well as package of agents and skills for software development. The core idea: Claude Code alone is a powerful agent framework. Claude Flow V3 turns it into a coordinated agent system by layering additional memory, routing, specialist agents, orchestration, and planning on top of each other - like from factory workers to a factory that makes factories.
The Skillsmith Agent Architecture has five layers:
| Layer | Component | Role |
|---|---|---|
| 1 — Foundation | Memory Persistence | SQLite + MEMORY.md for cross-session context |
| 2 — Infrastructure | Model Routing | haiku / sonnet / opus auto-selected by task complexity |
| 3 — Agents | Specialists | architect, coder, tester, reviewer, researcher, etc. |
| 4 — Orchestration | SPARC + Wave-Planner + Hive Mind | Planning and parallel execution |
| 5 — Custom Skillsmith Planning | Launchpad | 4-stage pipeline from issue to deployed code |
The jump from Claude Code V2 to V3 introduced three meaningful changes: intelligent model routing (right model, right task, every step), SPARC as a first-class planning mode for high-blast-radius work, and hive-mind configs versioned alongside code rather than generated ad hoc. This hive-mind capability improves the coordination and execution of code with reduced errors at speed. It enables more on-the-fly specialist agent definitions and the skills those specialists need to get work done, taking advantage of the Attention Is All You Need research finding.
The Launchpad Pipeline - Custom Skillsmith Tooling
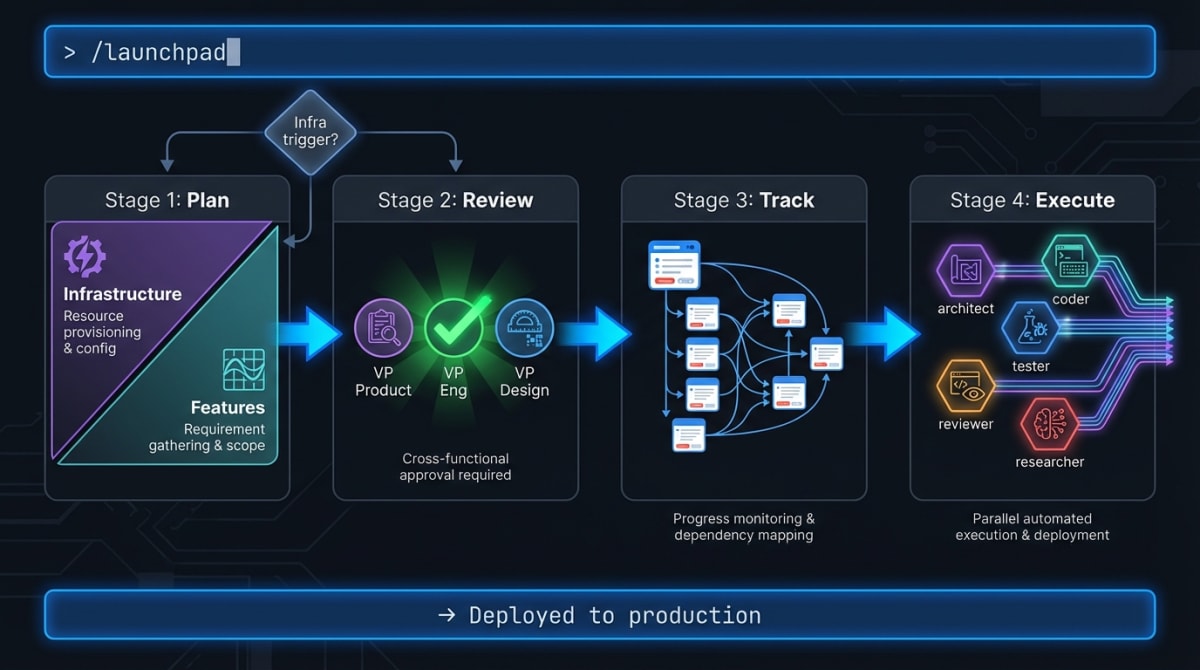
Launchpad is the end-to-end orchestrator skill. Using the Daisy-Chain skill framework, one super skill command drives the entire journey from Linear issues to deployed PR across four stages:
Stage 1 → Plan SPARC (infra) or Wave-Planner (features)
Stage 2 → Plan Review e.g. VP Product · VP Engineering · VP Design improve plan first
Stage 3 → Track Linear issues created, dependencies linked
Stage 4 → Execute Hive-mind agents implement in parallel with specialist configsBefore Stage 1 runs, there’s a Stage 0 routing decision. Launchpad inspects the trigger paths in your plan:
- Detects infrastructure triggers (
Dockerfile,.github/workflows/, hooks,vitest.config.ts,turbo.json…) - Infrastructure detected → SPARC path (deep research before anything else)
- Feature work → Wave-planner path (parallel agent swarm)
This matters because infrastructure is low-LOC, high-blast-radius. A 47-line change to a Docker entrypoint affects every developer’s daily workflow. That warrants a fundamentally different process than adding a new MCP tool.
Across all Skillsmith work, Launchpad generated 98 hive-mind YAML configs. Stage 2 (VP review) caught two critical bugs before a single line was written.
SPARC: Research Before Code
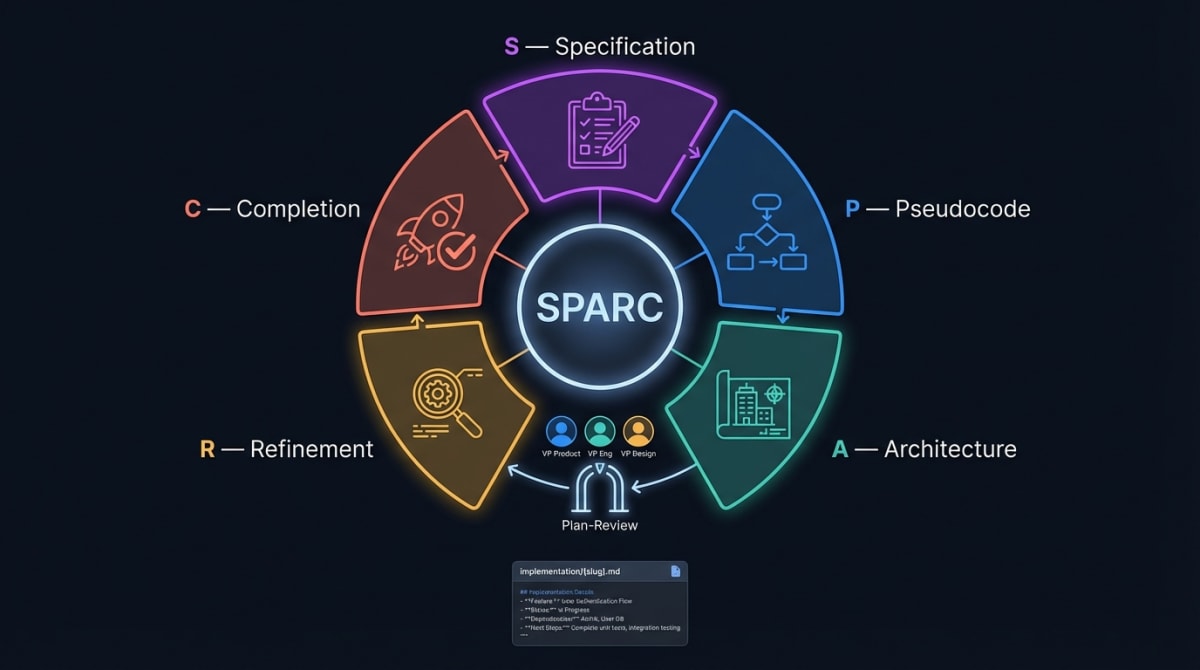
SPARC stands for Specification · Pseudocode · Architecture · Refinement · Completion. We made it mandatory for all infrastructure changes in Skillsmith.
The flow is deliberate and sequential:
- Researcher — reads all affected files, enumerates edge cases, fetches relevant documentation
- Architect — writes a full implementation plan covering root cause, acceptance criteria, exact code changes, and a rollback plan
- Plan-Review — three VP perspectives sign off before coding begins
- Coder agents — implement against the reviewed plan, not against a vague prompt
The value shows up in what gets caught. During one infrastructure sprint, SPARC research identified a single-sentinel fragility in our Docker build guard: it checked only core/dist for a successful build instead of both core/dist and mcp-server/dist. The build could pass while the MCP server binary was stale or missing. That bug lived at the architecture design stage, not in code. Without SPARC, it would have shipped.
Plan-Review: The Safety Net That Pays for Itself
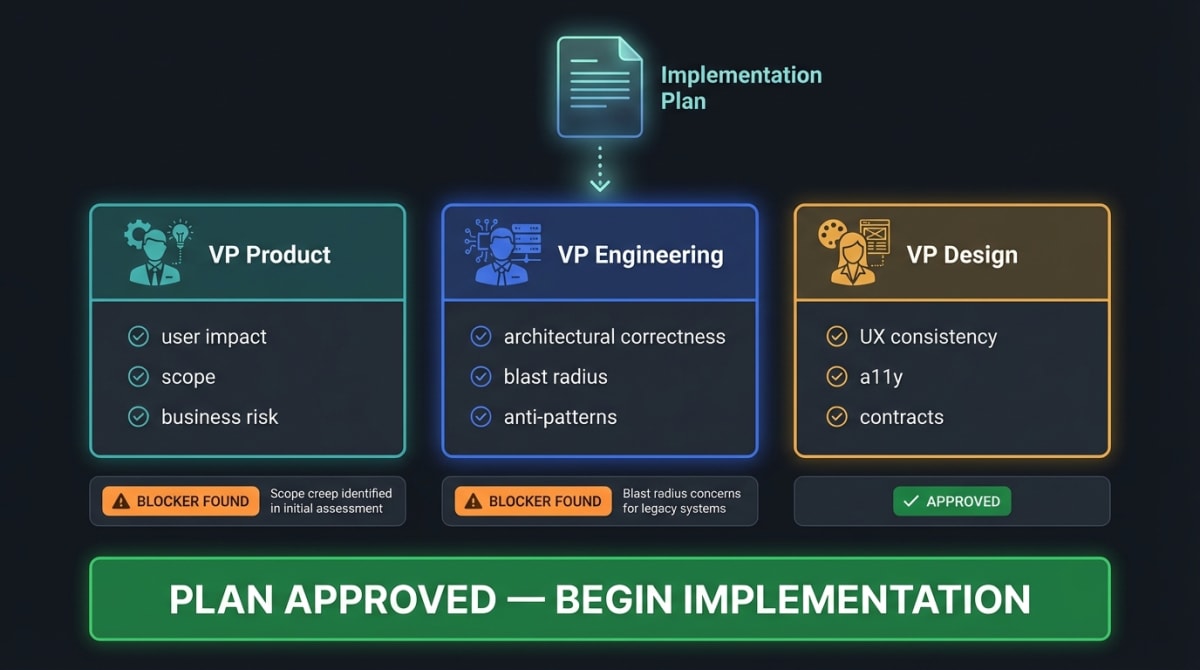
Stage 2 of every Launchpad run is Plan-Review: three simulated executive reviewers examine the plan before any implementation begins.
| Reviewer | Focus |
|---|---|
| VP Product | User impact, scope creep, business risk |
| VP Engineering | Technical correctness, architectural anti-patterns, blast radius |
| VP Design | UX consistency, accessibility, contract violations |
In one sprint alone, Plan-Review surfaced two catches that would have cost hours to debug:
Catch 1 — Data flow misread. A proposed refactor identified wildcardExpansionCount as a duplicate field and flagged it for removal. The VP Engineering reviewer traced the data flow and found it was the source — the accumulator that feeds high_trust_wildcard.total_paths_expanded downstream. Removing it would have silently zeroed all wildcard telemetry with no error thrown.
Catch 2 — Premature execution. The same refactor targeted a file that was 484 lines on main — under a 500-line limit set in all code reeviews, that would have justified a refactor should it have been over 500 lines. The relevant fields only existed on the feature worktree branch. Executing the plan against main would have been a no-op.
Cost of Plan-Review: ~5 minutes. Cost of catching either issue in production: hours + hotfix PR + incident report.
The ratio holds consistently. We now treat Plan-Review as non-negotiable for any change touching shared interfaces or response contracts. For more on composing agents and skills effectively, see the decision framework for agents and skills.
Wave-Based Feature Delivery
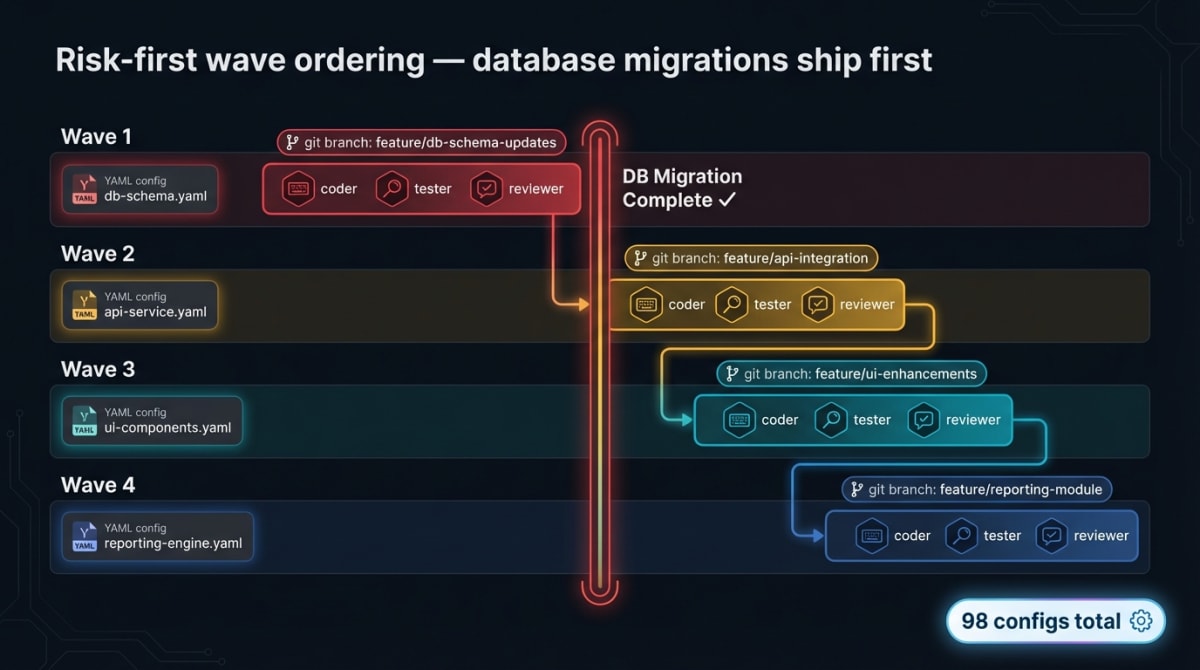
Feature epics get decomposed into sequential, dependency-ordered waves — each with its own branch and hive-mind YAML config.
Two principles govern wave ordering:
Risk-first. Database migrations always ship in Wave 1, regardless of implementation readiness. The schema is the foundation everything else sits on. Shipping application logic before the schema is locked is asking for conflicts.
Branch stacking. Wave N+1 branches from Wave N’s branch, not from main. When Wave N is squash-merged, Wave N+1 cleanly sits on top. Branching multiple waves from main in parallel leads to merge conflicts that are annoying to untangle.
A real example — Cross-Ecosystem Skill Discovery:
Wave 1 DB migration ← risk-first: schema before everything
Wave 2 Indexer changes ← depends on Wave 1 columns
Wave 3 MCP tool updates ← surfaces new fields to search
Wave 4 UI / docs ← safe to parallelize lastEach YAML config specifies topology (hierarchical vs. mesh), max agents, execution strategy, preflight checks (correct branch, Docker container running, last migration applied), and per-agent tasks with acceptance criteria. The configs live in .claude/hive-mind/ alongside the code they implement, versioned in git.
Across all Skillsmith work: 98 hive-mind configs generated, representing the full parallel execution history of the product.
Memory and Cross-Session Learning
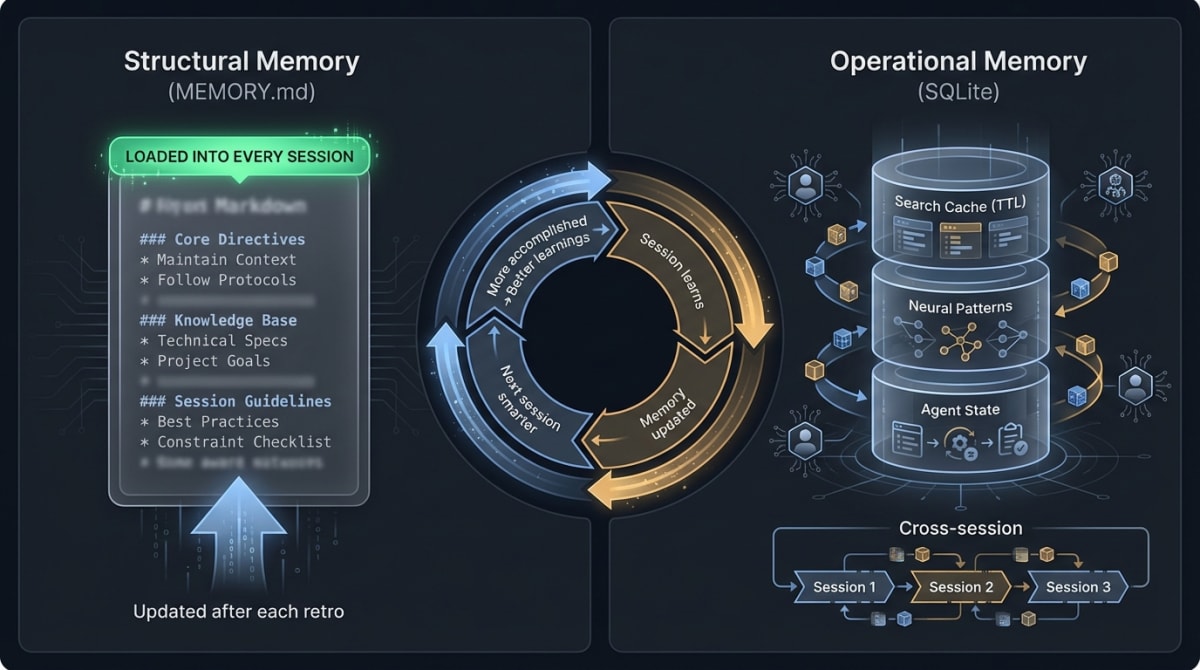
The hardest problem in agentic AI development is session amnesia. Each new Claude session starts from zero by default. Over 534 sessions, this would compound into thousands of repeated corrections and re-explanations.
Claude Flow V3 attacks this at two levels.
Level 1 — Structural memory (MEMORY.md). A hand-curated knowledge file loaded into every session’s system prompt:
- Project conventions and Docker-first rules
- Hard-won debugging insights (the root cause of git-crypt smudge filter branch switching, for example, took time to isolate — it lives in MEMORY.md now)
- API patterns, model choices, architectural decisions with links to their ADRs
- Maximum 200 lines, which can include references to other documents
Every session starts as smart as the best previous session.
Level 2 — Operational memory (SQLite). Claude Flow V3’s MCP server persists agent state and neural patterns across sessions: search result caching with TTL, neural pattern training on query behaviour, cross-agent knowledge sharing.
The result compounds:
Session learns → MEMORY.md updated → Next session smarter
→ Fewer corrections → More ambitious work → Better learningsSkills as the Developer Interface
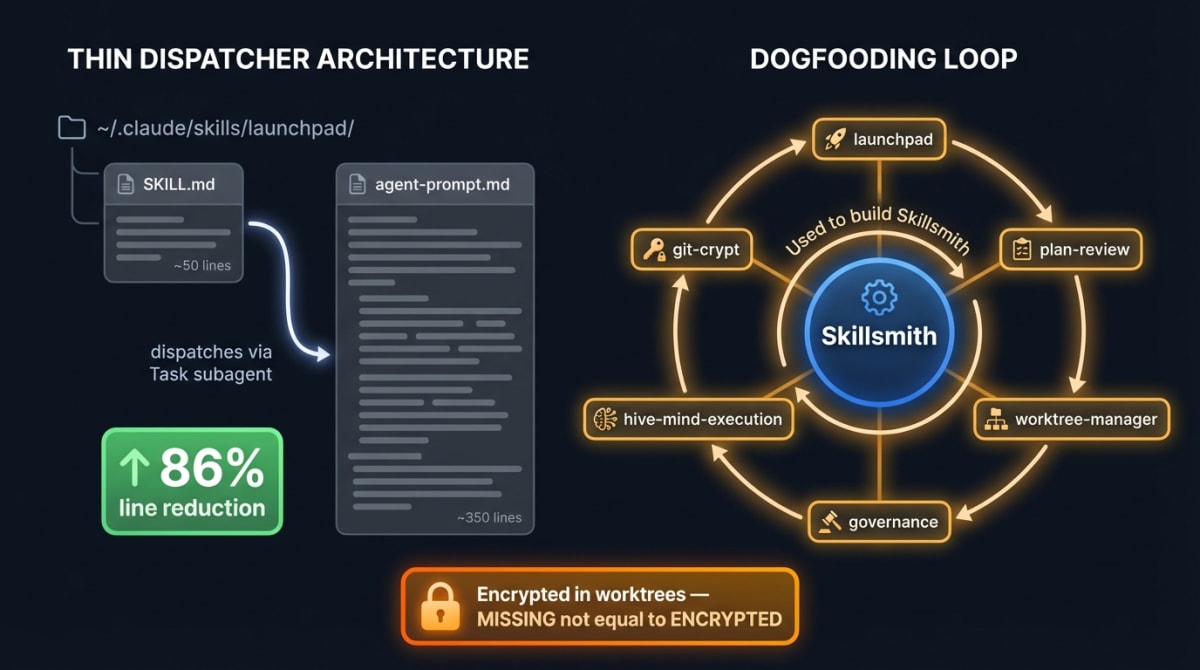
Skills are the user-facing surface of Claude Flow V3 — and the product Skillsmith sells. This creates a clean dogfooding loop: the skills that build Skillsmith are the product.
We settled on a Thin Dispatcher Pattern for skill architecture: a two-file design that keeps the system prompt lean and logic versioned separately.
~/.claude/skills/<name>/
SKILL.md ~50 lines — frontmatter + dispatch only
agent-prompt.md ~350 lines — full agent instructionsThe SKILL.md triggers the general-purpose subagent and passes the path to agent-prompt.md. This gives an 86% line reduction from the original monolithic approach, and means the full instructions are only loaded when the skill is actually invoked.
The Skillsmith development stack uses six project-level skills:
| Skill | Role |
|---|---|
launchpad |
End-to-end orchestration of every feature |
plan-review |
VP review before implementation |
worktree-manager |
Parallel branch management across waves |
governance |
Standards enforcement on every PR |
hive-mind-execution |
Executes wave YAML configs |
git-crypt |
Encrypted skill readability check in worktrees |
For a detailed breakdown of how to structure skills for composability and discovery, see how Skillsmith indexes and curates skills.
Results

By the numbers as of February 2026:
| Metric | Value |
|---|---|
| Hive-mind YAML configs | 98 |
| Git commits shipped | 159 |
| Linear issues tracked | 159 |
| Claude Code sessions | 534 |
| Total session hours | ~509 hrs |
| Goal achievement rate | 94% |
| Critical bugs caught pre-code by Plan-Review | 2 |
| ADRs documenting architectural decisions | 109+ |
What Claude Flow V3 actually unlocked, translated from metrics to practice:
- Parallelism at scale — 4-wave epics delivered in hours rather than weeks, with agents working independent waves concurrently
- Institutional memory — every session builds on the last; the system gets smarter permanently rather than starting fresh each time
- Pre-code safety — SPARC + Plan-Review catches architectural bugs before they touch the codebase, which is the only stage where they’re cheap to fix
- Dogfooding quality loop — the skills that build Skillsmith are the product, which means quality improvements feed directly back into the toolchain
- Cost-efficient routing — haiku handles simple queries, sonnet handles most implementation, opus handles architectural decisions; the right model at every step
What’s Next
Three things on the roadmap that flow directly from what we learned:
Autonomous deploy pipeline. The agent currently owns branch → PR → merge, but a human still approves the final deploy. The next step: agent owns the full chain through deploy and Linear close, with no human in the loop for routine changes.
Self-healing ops layer. Continuous sync between Linear state and CI/CD reality. When CI is red, an agent diagnoses, creates a Linear issue, and proposes a fix without waiting for a morning standup.
Cross-ecosystem skill discovery. The indexer currently targets GitHub SKILL.md files. The next expansion: surface skills from MCP servers, npm packages with Claude integrations, and GitHub Actions — anywhere structured agent instructions live.
Frequently Asked Questions
What is Claude Flow V3?
Claude Flow V3 is a multi-agent orchestration framework that ships as an MCP server for Claude Code. It layers five components — memory persistence, model routing, specialist agents, orchestration tools (SPARC, wave-planner, hive mind), and the Launchpad pipeline — to turn Claude Code from a single-agent assistant into a coordinated engineering system capable of running parallel agent swarms, maintaining cross-session memory, and catching architectural bugs before they reach the codebase.
What is SPARC methodology in Claude Code?
SPARC (Specification, Pseudocode, Architecture, Refinement, Completion) is a research-first planning methodology for high-risk code changes. In practice: a Researcher agent reads all affected files and enumerates edge cases, an Architect writes a complete implementation plan with acceptance criteria and a rollback plan, a Plan-Review step gets sign-off from multiple perspectives, and only then do Coder agents implement. SPARC is most valuable for infrastructure changes — low line-count, high blast-radius work where bugs are cheapest to catch at the design stage.
What is Plan-Review and how does it prevent bugs?
Plan-Review is Stage 2 of the Launchpad pipeline. Before any code is written, three simulated executive reviewers (VP Product, VP Engineering, VP Design) examine the implementation plan and surface blockers, anti-patterns, conflicts, and regressions. In Skillsmith’s development, a single Plan-Review session caught a data flow misread that would have silently zeroed all wildcard telemetry, and a premature refactor that would have been a no-op against main. Each catch took 5 minutes in review versus hours in production.
How does wave-based development work with Claude Flow V3?
Wave-based development decomposes a feature epic into sequential, dependency-ordered waves — each with its own git branch and hive-mind YAML config. Two key principles: risk-first ordering (database migrations always ship in Wave 1 regardless of implementation readiness), and branch stacking (Wave N+1 branches from Wave N’s branch rather than main, preventing squash-merge conflicts). Each wave’s YAML config specifies agent topology, preflight checks, and per-agent tasks with acceptance criteria.
How does Claude Flow V3 maintain context across sessions?
At two levels. First, MEMORY.md — a hand-curated file loaded into every session’s system prompt that stores project conventions, debugging insights, architectural decisions, and API patterns. Every session starts as smart as the best previous session. Second, Claude Flow V3’s MCP server persists agent state in SQLite across sessions, including search caching, neural pattern training on query behaviour, and cross-agent knowledge sharing. Together these achieved a 94% goal achievement rate across 48 tracked sessions.
How is Skillsmith built using its own skills?
Skillsmith uses six project-level agent skills for its own development: launchpad orchestrates every feature end-to-end, plan-review gates implementation with VP-perspective review, worktree-manager handles parallel branch management across waves, governance enforces engineering standards on every PR, hive-mind-execution runs wave YAML configs, and git-crypt manages encrypted skill access in git worktrees. Every pattern shipped to Skillsmith users is validated against the development team’s own daily workflow first.
The skills, YAML configs, and ADRs referenced in this post are part of the Skillsmith development workflow. If you’re building with Claude Code and want to explore the patterns here, the Skillsmith MCP server is a good place to start.